"AI 학습에 필요한 ‘데이터 특징 가지수’ 늘려도 계산 단순함 유지"
이준구 한국과학기술원(KAIST) 전기및전자공학부 교수 연구팀은 ‘비선형 양자 기계학습 AI 알고리즘’을 개발했다고 7일 밝혔다.
AI가 이미지, 소리, 텍스트 등을 인식하고 필요한 기능을 수행하기 위해서는 기계학습이 필요하다. 기계학습은 AI가 수많은 데이터들을 종합해 ‘특징’을 분류하는 과정이다. 가령 개를 인식하기 위해서는 여러 개 이미지들을 통해 ‘귀 모양’ ‘입 모양’이라는 특징을 분류한다. 이를 바탕으로 새로운 개 이미지가 입력됐을 때 그것이 개인지 아닌지 구분할 수 있다.
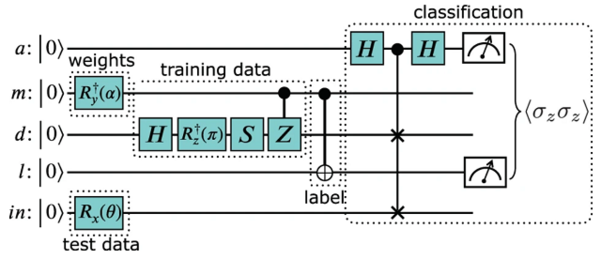
연구팀은 양자컴퓨터의 장점을 활용해 특징 개수가 늘어나도 효율적인 계산을 수행할 수 있는 새로운 기계학습 알고리즘을 개발했다. 양자컴퓨터의 연산단위인 ‘큐비트(qbit)’는 0과 1을 중첩해서 동시에 표현할 수 있기 때문에 0 또는 1만 표현할 수 있는 현재 컴퓨터보다 이론적으로 훨씬 높은 성능을 보일 것으로 예상된다. AI 학습에 필요한 특징 개수가 늘어나도 많은 비트 용량 대신 적은 큐비트만으로도 계산을 처리할 수 있다는 게 연구팀의 설명이다.
연구팀의 알고리즘은 단순하게 분류돼있는 데이터들을 양자컴퓨터 연산을 이용해 더 많은 특징별로 세분화할 수 있는 수학적 함수가 포함돼있다. 연구팀은 "데이터의 특징 가지수를 늘려도 계산이 크게 복잡해지지 않는다"고 설명했다. 특징 개수가 10배, 100배, 1000배 늘어날 때 각각 필요한 계산이 로그값인 2배, 3배, 4배만 복잡해지도록 했기 때문이다.
연구팀은 IBM이 초전도(超電導) 시스템을 기반으로 만들어 클라우드로 제공한 5큐비트짜리 양자컴퓨터에서 이 알고리즘을 실제로 시연하는 데 성공했다.
연구에 참여한 박경덕 KAIST 연구교수는 "향후 수백 큐비트 양자컴퓨터가 상용화되면 복잡한 비선형 데이터의 패턴 인식 등을 위해 이 알고리즘이 활발히 사용될 것"이라고 기대했다.
연구성과는 네이처 자매지인 ‘NPJ 퀀텀 인포메이션(NPJ Quantum Information)’에 지난 5월 15일 게재됐다.
July 07, 2020 at 08:00AM
https://ift.tt/31SdA08
양자컴퓨터 맞춤형 AI 나올까… 새 기계학습 알고리즘 개발 - 조선비즈
https://ift.tt/2UCS7nr
No comments:
Post a Comment